|
|
VCX. Automatic byte order detection |

|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
VCX libraryproduct infosupport |
EndiannessTerm endianness usually means byte ordering in memory storage of data types larger than one byte. For example, a word (two bytes) hexadecimal value 0x1873 may be stored in adjacent memory bytes as the following: 1) least significant byte (LSB) followed by most significant byte (MSB), also called little-endian layout:
2) MSB followed by LSB, also called big-endian layout:
Same applies to larger data types, for example integer (four bytes) value 0x8E160A3D may be stored as: 1) little-endian layout:
2) big-endian layout:
There are also other layouts possible, like middle-endian, but they are out of scope of this article. Please refer to http://en.wikipedia.org/wiki/Endiannessfor more information about endianness. PCM audio samples in audio streamsIn this article we define PCM sample as a 16-bit integer value, ranging from -32768 to +32767 decimal, or from 0x8000 to 0x7FFF hexadecimal. Audio stream consists of adjacent PCM samples: [sample N] [sample N+1] [sample N+2] [sample N+3] ... Stream may contain more that one channel, in which case they interleave in the steam, but in this article we deal with mono streams only, as automatic detection of byte order in non-mono streams using the algorithm described below may not always produce good results. Let say we want to store the following PCM samples in memory: 0x0234, 0x0123, 0xFEDC and 0xF987. Samples in mono streams are always stored one by one without interleaving. Depending on organization of memory storage it could be done as: 1) little-endian layout:
2) big-endian layout:
Note the sample boundaries, marked with different colors here. Depending on layout bytes may be stored in different order within the boundary, but they never "cross" it. That is important for later discussion.
When dealing with uncompressed audio streams, especially when they are being transferred over network, care must be taken to retain proper byte order of audio samples in the stream. Not only the byte order may differ, but the boundary of samples may be unknown. This may happen when data is being transferred over unreliable protocol, like UDP. Let assume we have received the following sequence of bytes from the network:
(Yes, that is PCM samples in big-endian layout from the previous example plus one additional byte, but our algorithm must work correctly without this hint :) We know there are two possible interpretations of this sequence (big- and little-endian), but if we do not know the boundaries of samples, two more additional combinations are possible, making it four different interpretations in total: 1) little-endian, boundaries as is (last sample is ignored, since we have only one byte for it. This last byte will be added at the beginning of next sequence of bytes when it will be received from the network):
2) big-endian, boundaries as is (last sample is ignored, since we have only one byte for it. This last byte will be added at the beginning of next sequence of bytes when it will be received from the network):
3) little-endian, adjusted boundaries (we simply ignore the first byte):
4) big-endian, adjusted boundaries (we simply ignore the first byte):
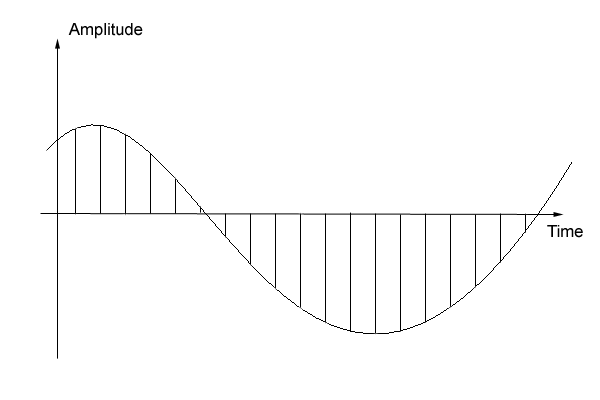
Notice that sequence of bytes is always the same, and it only the matter of interpretation how to convert it into PCM samples. Now our task is to decide, which interpretation (byte order and boundaries) should be chosen as proper representation of audio signal. Let take a look at a sine with PCM samples taken periodically. Each vertical line represents one PCM sample:
As you can see, adjacent samples do not differ much, but rather have a tendency to change slowly into some direction. That assumes audio signal has enough low frequencies for selected sampling rate. We can use that tendency as a basis of our algorithm. We calculate the sum of differences between adjacent samples in all four interpretations as the following: 1) little-endian, boundaries as is:
2) big-endian, boundaries as is:
3) little-endian, adjusted boundaries:
4) big-endian, adjusted boundaries:
The final step is to select the interpretation with minimal sum of differences between samples. In our case it is the interpretation number two — big-endian, boundaries as is (exactly as hint has suggested :). Notice, that interpretations 2) and 3) are almost similar, same as interpretations 1) and 4). That is because shifting the boundaries by one byte is almost similar as switching from little- to big-endian, when samples are audio samples, i.e. do not differ much from each other. As you can see, even for such a sort sequence of bytes it is possible to detect proper order of PCM audio samples. The longer the sequence, the better should be the guess. In real applications it is usually enough to analyze about 1/20 sec of audio signal (400 samples for 8000Hz sampling rate). Please also note, that if you are using reliable protocol (like TCP), the boundaries and byte order may be guessed only once and then applied to all subsequent data. When using unreliable protocol (like UDP), it may be necessary to apply the guess at each sequence (data packet).
Our VC components and VCX library products do include byte order and samples boundaries auto detection algorithm described above. By default it is turned off, so you have to choose one of the following methods if you wish to enable it for incoming and/or outgoing streams:
Assign the selected property value to streamByteOrderInput and/or streamByteOrderOutput property
to specify which method to be used with incoming or outgoing data.
|